
Performance Testing
随着部门人手的增加,终于有了一些时间可以做性能测试,需要对分布式数据库中间件做一个压测,把得到的结果当作一个基线,来比较版本之间的性能变化。
在学习和实战中,慢慢发现,对性能测试的理解并不如自己想的那么清晰,对基本概念和理论的混淆,导致对测试结果的不够自信,过程中也走了很多弯路。
所以这一次,一起梳理下性能测试的基本理论和实践过程。
负载测试、压力测试和性能测试的异同
负载测试(Load testing)、压力测试(Stress Testing)和性能测试(Performance Testing),这三个概念常常引起混淆,难以区分,从而造成不正确的理解和错误的使用。之前也有不少讨论,比较有名的,应归为 Grig Gheorghiu’s 的两篇博客:
简单的概括一下三者就是:
- 负载测试是通过改变系统负载方式、增加负载等来发现系统中所存在的性能问题。负载测试是一种测试方法,可以为性能测试、压力测试所采用。负载测试的加载方式也有很多种,可以根据测试需要来选择。
- 性能测试是为获取或验证系统性能指标而进行测试。多数情况下,性能测试会在不同负载情况下进行。
- 压力测试通常是在高负载情况下来对系统的稳定性进行测试,更有效地发现系统稳定性的隐患和系统在负载峰值的条件下功能隐患等。
性能调优
系统是否具有高性能的运行特征,不仅取决于系统本身的设计和程序算法,而且取决于系统的运行环境。系统的运行环境会依赖于一些关键因素,例如:
- 系统架构,如分布式服务器集群还是集中式主机系统等。 硬件配置,如服务器的配置,CPU、内存等配置越高,系统的性能会越好。
- 网络带宽,随着带宽的提高,客户端访问服务器的速度会有较大的改善。
- 支撑软件的选定,如选定不同的数据库管理系统(Oracle、MySQL等)和web应用服务器(Tomcat、GlassFish、Jboss、WebLogic等),对应用系统的性能都有影响。
- 外部负载,同时有多少个用户连接、用户上载文件大小、数据库中的记录数等都会对系统的性能有影响。一般来说,系统负载越大,系统的性能会降低。
从上面可以看出,使系统的性能达到一个最好的状态,不仅通过对处在特定环境下的系统进行测试以完成相关的验证,而且往往要根据测试的结果,对系统的设计、代码和配置等进行调整,提高系统的性能。许多时候,系统性能的改善是测试、调整、再测试、再调整、……一个持续改进的过程,这就是我们经常说的性能调优(perormance tuning)。
系统性能描述
描述一个系统的性能从来不是一句话或是一个数值的事。在IEEE的定义中:性能是系统或组件在给定约束中实现的指定功能的程度,诸如速度、正确性、内存使用等。
所以性能测试报告中,对系统性能的描述应该是多方面的,如:执行效率、稳定性、兼容行、可靠性、可扩展性容量等;其中,执行效率通过并发用户数、响应时间、吞吐量、成功率、资源消耗综合体现。
并发
长连接压测的并发大概有三种方法:
- 单进程单线程进行串行执行,进行多进程并发;
- 单进程多线程模式;
- 连接池模式;
实际上,所有的并发不可能做到完全同步,压测过程中由于各种影响,比如:各线程初始化速度不一样,连接数不够,处理速度不一样等,导致在并行节奏上相互有了偏差, 这种现象在系统接近性能瓶颈时,会更加突出。 这里引入“狭义并发”和“广义并发”的概念。
“广义的并发实际上是在一个时间内操作事务的虚拟用户,而狭义的并发指的是单位时间内向系统发起请求的虚拟用户,前者是“存在”,后者是“请求”,勿容置疑,压力不仅仅受成功发出请求的用户带来的压力,同时也受“存在”的用户影响。”
这样看来,工具中的线程数设置,更偏像是广义并发,代表着在压测时间段内虚拟用户总数,这也是并发原始值。
而在后续的压测过程中,在单位时间内,并发数可能会动态变化,这里是狭义并发。
当工具产生的压力远未到系统性能瓶颈时,理论上,狭义并发=广义并发=工具线程数;当压力增加,系统响应时间增长,部分线程的请求处理正常,部分线程可能请求超时,那么同一单位时间内,同时向系统发起请求的用户数就不等于线程数了。
吞吐量的计算
在性能测试中,吞吐量的计算有两种常见的公式:
公式1: 吞吐量=并发数/平均响应时间
公式2: 吞吐量=请求总数/总时长
我们可以从 C = nL/T 推导出 公式1 = 公式2 :
并发 = (请求总数 * 平均响应时间)/ 总时长
—-> 并发 / 平均响应时间 = 请求总数 / 总时长
下面用真实的压测数据来计算一下两种公式求解的QPS,然后反推一下实际并发量:

实际并发确实稍低于工具线程数。
因此,在不同的应用场景下,应当选择不同的公式来计算吞吐量:
- 在单接口压测时,我们用“请求总数/总时长”得到吞吐量;然后再用“吞吐量*平均响应时间”得到实际并发,此举可用来观察系统实际承受的并发;
- 在多接口压测时,由于短板效应,同一个流程中的所有接口获得的请求总数和总时长都一样,显然“请求总数/总时长”计算各个子接口的吞吐量不合适,所以改用“并发/平均响应时间”,其中的并发数应在压测工具中埋点统计,不可简单使用工具线程数。
最佳线程数
性能压测的情况下,起初随着并发量的增加, QPS 会上升,当到了一定的阈值之后,并发量增加 QPS 并不会增加,或者增加不明显,同时请求的响应时间却大幅增加。这个阈值我们认为是最佳线程数。
影响最佳线程数的主要因素是 IO 和 CPU 。
服务器端最佳线程数量 = ((线程等待时间+线程cpu时间)/线程cpu时间) * cpu数量
有两种极端,纯 IO 的应用,比如 proxy ,则线程数量可以开到非常大(实在太大了则需要考虑线程切换的开销),这种应用基本上后端(比如这个 proxy 是代理搜索的)的 QPS 能有多少,proxy 就有多少。
另一种是耗 CPU 的计算,这种情况一般来讲只能开到 CPU 个数的线程数量。但是并不是说这种应用的 QPS 就不高,往往这种应用的 QPS 可以很高。
这里测试的数据库中间件的 QPS 瓶颈显然是 IO 而不是 CPU ,所以这里通过调整连接池的配置,可以极大的提高 QPS 。
实践过程
这里使用的压测工具是 sysbench ,监控工具是 nmon 。
- 先进行性能调优:
- 调整线程池的配置和拆分规则的配置,找到性能最优的配置方案。(这里遇到很多坑,在进行长时间的压测之前,一定要先进行性能调优,调整方案,才能达到事半功倍的效果)
- 先取线程数从 16, 32, 64, 128 … 一直到 1024,每个线程数并发运行较短时间 (1h),锁定最佳线程数的大致的范围,取 4 个线程数。
- 确定配置和线程数后,采用不同场景进行测试:
根据取得 4 个线程数,再进行长时间 (4h, 8h)的只读/只写操作 ,取得较为准确的性能测试数据。
改变原始数据量,采用最佳线程数并发,再进行长时间 (8h) 的只读/只写操作,取得较为准确的性能测试数据。
- 改变中间件支持的不同的拆分类型,采用最佳线程数并发,再进行长时间 (4h) 的只读/只写操作,取得较为准确的性能测试数据。
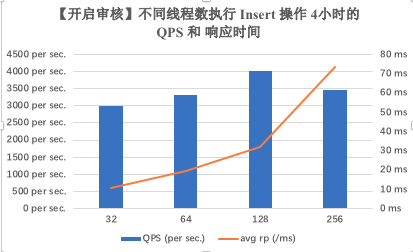
对性能测试数据进行分析,对系统资源的监控数据进行分析。
编写性能测试报告,将复杂的数据用浅显易懂的图表展示。
到这里,一个完整的性能测试才完成了。
最后
对实践过程说的比较简略,因为这里主要是针对性能测试的理论和方法,而不是性能测试工具的使用。这些内容具体可以去网上搜 sysbench 的教程和 nmon 的教程,就不详述了。
参考文献:
负载测试、压力测试和性能测试的异同
http://blog.csdn.net/kerryzhu/article/details/3515714
早知道早幸福——从压测工具谈并发、压力、吞吐量
http://wetest.qq.com/lab/view/177.html